
最近幻方发布的 DeepSeek R1 模型震惊了全世界,干崩了美股英伟达,也让 CloseAI OpenAI 鸭梨山大,以至于奥特曼火速宣布 o3-mini 将免费使用。

幻方其实是一家做量化交易的私募基金,靠算法和自动交易在 A 股赚钱。创始人是 85 后浙大学霸梁文锋。

这家公司在前几年屯了很多英伟达显卡,用来打游戏,哦不对,是用来训练 LLM。

在某种东方神秘力量的加持下,他们研制出了新的算法配方,让训练成本大幅下降,而且训练出来的效果很好,最新发布的 DeepSeek R1 几乎和 o1 打平。
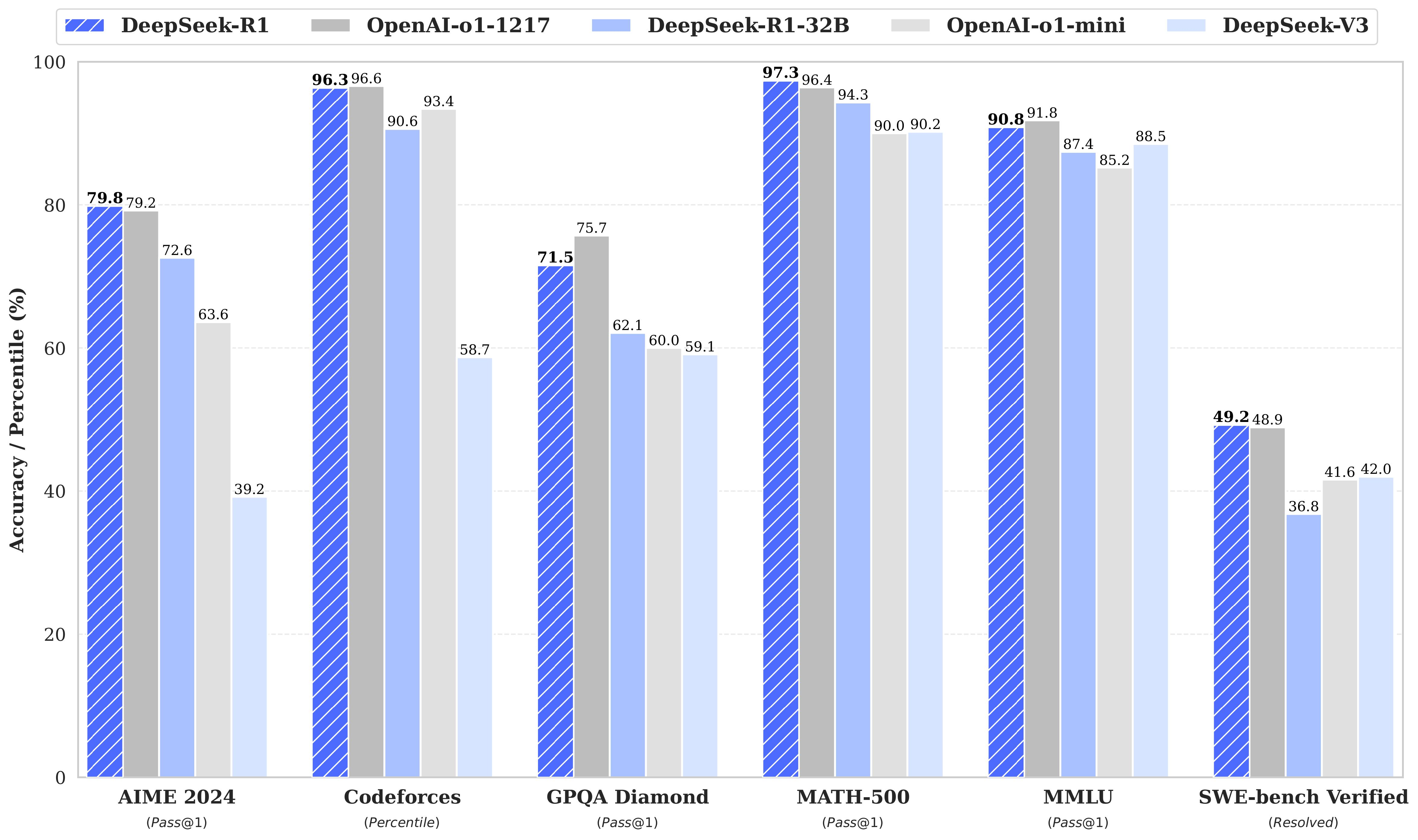
而且,他们的代码遵循 MIT 开源协议,完全开放,可以随意拿去商用,不用给钱。
公司赚了大钱,开始为人类做贡献了,格局简直拉爆。
通常,我们使用的 AI 平台都是客户端,运算是在它们的远端服务器上完成。今天,我准备把 DeepSeek R1 搬到 MacBook 的本地来部署。所谓本地,就是让 AI 模型住到自己电脑里,靠自己电脑的算力来支撑模型的运行,无需连接网络。
这样,即便在飞机上没网络,还是去了火星和地球信号失联,我都能随时召唤大模型,让它协助我计算两位数的加减乘除,挑战小猿口算王者称号,以便吊打全班同学。
一、安装 Ollama
Ollama 是一个可以在本地运行大语言模型(LLM)的命令行工具,我们今天就用它。
很多人可能一听到命令行就头大,别担心,其实用起来很简单。

安装很简单,一点也不头大。首先进入 Ollama 的官网:
看到中间的神兽图标了吧,点击下方的「Download」,去下载 macOS 版本。
国内网络用浏览器直接下载可能会比较慢,你可以把下载链接复制到迅雷里下载,速度很快。
下好后解压缩,先把这个神兽图标拖到「应用程序」里。
然后,打开 Ollama,点中央的 Install,这时候需要输入 Mac 的解锁密码。
出现下面这样的提示就说明装好了。
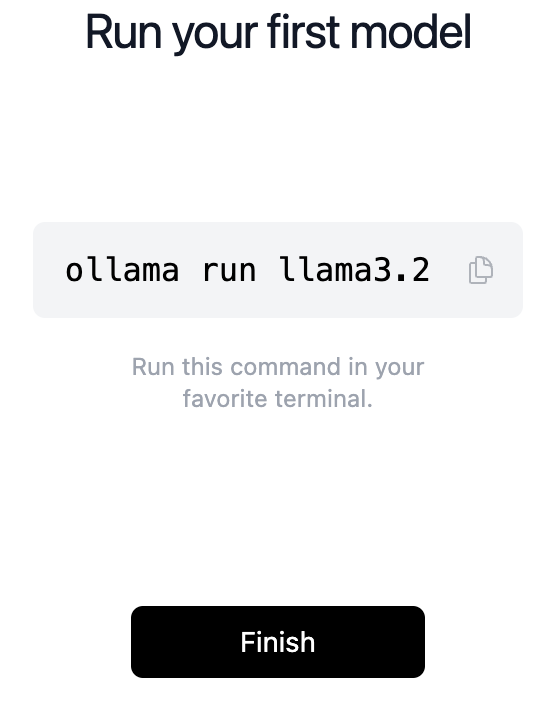
二、下载模型
现在可以去下载模型了。进入这个页面:
里面列举了各种参数的 DeepSeek R1 模型,以及它们各自的运行命令。
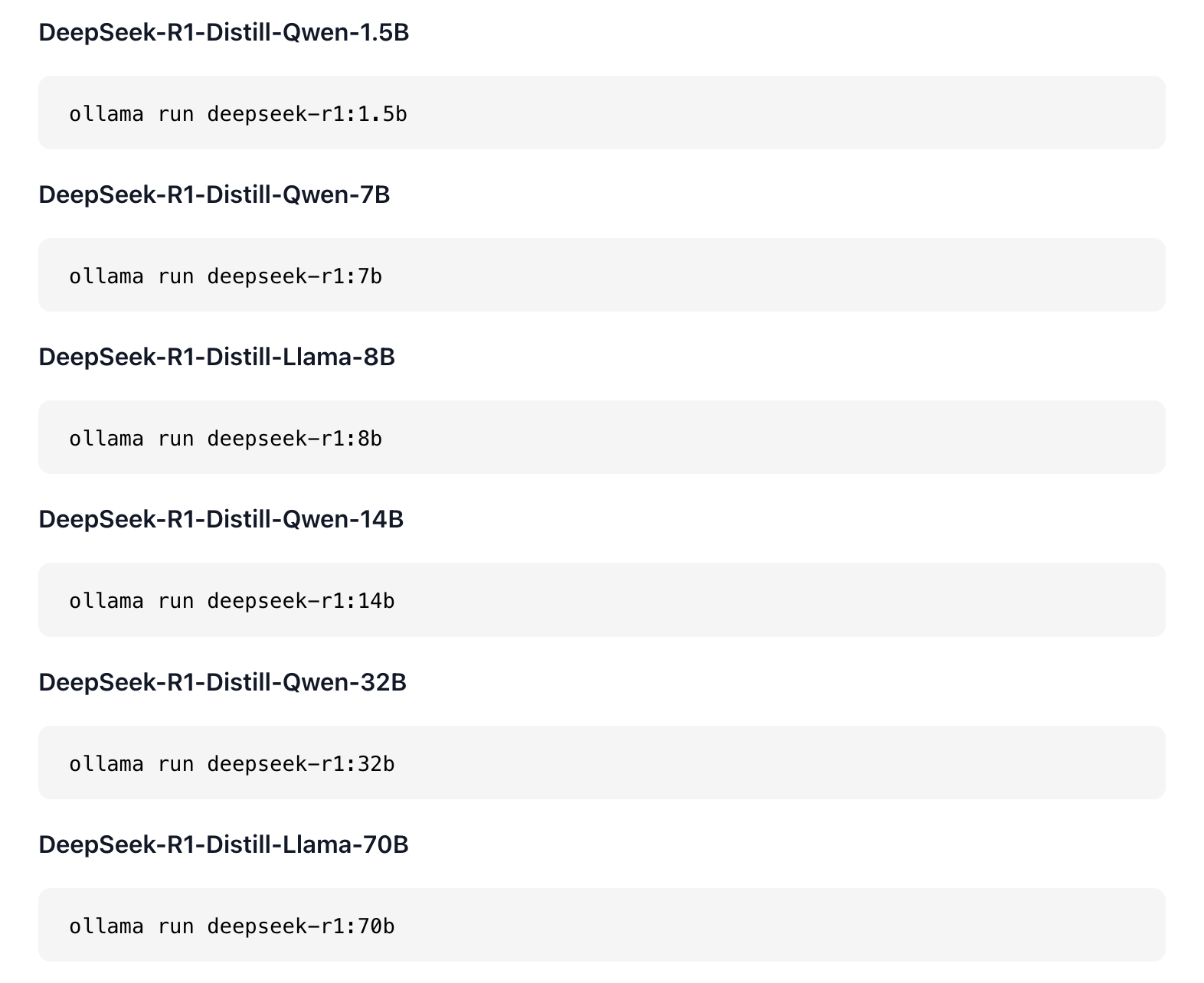
DeepSeek 原版是 671b 参数。b 代表 billion,671b 也就是 6710 亿参数,一般电脑跑不下来,头铁的可以去试试。

所以,我打算试下 32b 的蒸馏模型,挑战一下这台 48G M4 Pro 的 MacBook Pro。
啥是蒸馏模型?是不是得把电脑放到锅里蒸一下?
不是。蒸馏模型是一种把大模型的知识传授给小模型的方法,也叫做「知识蒸馏」,由诺奖大佬辛顿等人提出。
技术原理比较复杂,你可以理解为把大小模型都放到铁锅里进行大乱炖,在三味真火的加持之下,最终炼制成姿势水平接近大模型的小模型,以便能部署在配置较低的平台上。

好了,现在我们打开苹果电脑里的终端,输入下面的命令,下载并运行 32b 模型:
ollama run deepseek-r1:32b
然后就开始下载模型了。有点大,差不多 19G,慢慢等吧。

三、开始交互
模型下载好后就开始自动运行了。
你可以直接在终端中输入文字,和大模型交流。

我简单试了下,效果不错,直接就是 R1 的深度思考模式,能看到模型的思考过程,很有意思。
这个 32b 的模型在我的 M4 Pro 上生成内容速度不错,已经很够用了,下次我准备继续压榨下机器,挑战一把 70b。
四、美化聊天
到这,模型就已经成功跑起来了。但上面这种命令行聊天的界面实在是不舒服,我得去找一个比较美观的聊天前端工具,就用之前我们用过的 ChatX 吧。
苹果商店就有,免费的,但国区似乎下架了,得使用其他地区的 Apple ID 下载。

打开 ChatX,在设置中找到「API 服务器配置」。
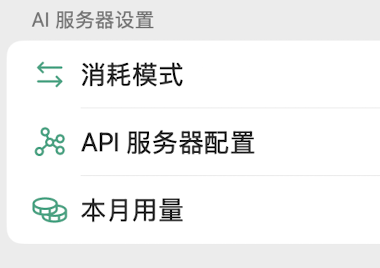
进入 API 服务器配置之后,找到有关「Ollama」的配置。默认已经填好了 Ollama 的 API 地址和端口了,不用管。然后在「自定义模型」中输入模型名称。
这里我输入刚下好的 deepseek-r1:32b,你下的啥就输入啥。

点击「验证一下」,如果提示成功就没问题了。
回到 ChatX 的主界面,创建一个新聊天,并选择刚才设置好的 deepseek-r1:32b模型,就可以开始愉快的聊天了。
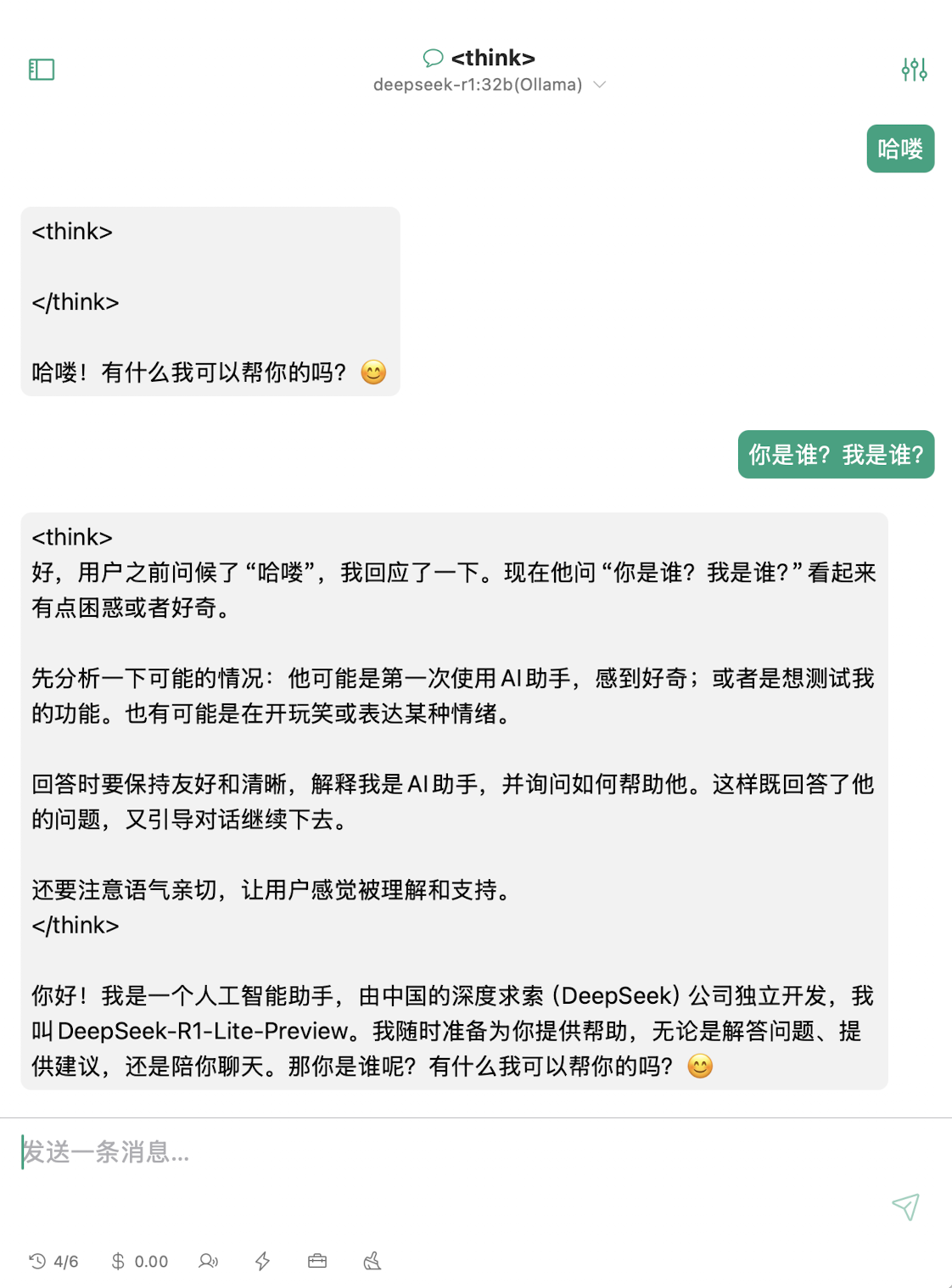
可以看出 ChatX 对聊天内容的优化不是很好,思考内容没做格式化就直接显示了出来,看着不太舒服。如果你有更好用的聊天前端软件,也欢迎在留言区交流。
好了,今天就写到这。大过年的,来都来了,不妨都去试一试

站长研究70b没,同配置。另外发现了个叫AnythingLLM的可用做前端,能做知识库。
我思考了下还是没弄,32b的输出速度10token/s,要是上70b,可能就卡的不行了。AnythingLLM是个好东西,最近试了下,搭建本地知识库很方便~